Facts About Big Data & Infycle’s Expertise Of Big Data Hadoop Training In Chennai
Statistics uncover that 16% of the organizations have the required analytics ability set up to deal with big data ventures. Experts are scrambling to get prepared and guaranteed in what’s relied upon to be the hottest new tech skill: Hadoop.
With squads of Big Data experts, Infycle’s turned out to be one of the best Big Data Hadoop training in Chennai whose Training course and certification is intended to give you skills in building amazing big data applications utilizing Hadoop by performing assignments on the real time Hadoop cluster.

Excelling Big Data Hadoop Training In Chennai – Way To Become Big Data Specialist!
Hence to excel in this industry and compete with a lot of skilled people, learning Big Data Hadoop Training in Chennai is a primary chore for all job seekers. Those who join Big Data course in Chennai, can learn and implement real time user cases, earn knowledge on maintaining data in HDFS, overall MapReduce architecture as well as HDFS infographic.
For learning the top technologies for their career, one must search for best and trusted software training institutes around them. Suppose a person is interested in learning Big Data Hadoop Training in Chennai, he/she must compare and choose the right Big Data Hadoop Courses package from the best software training organization in Chennai.
Further learning these vast data analytics concepts is nevertheless an easier task. Hence being trained up from highly qualified and experienced teaching experts, then one can accomplish his/her dream job come true.
Big Data Training In Chennai With Infycle Technologies!
Certificate Course With Infycle Technologies!
| Apr 1st | Mon-Fri(21 Days) | Timing 10:00 AM to 12:00 PM (IST) | Enroll Now |
| May 1st | Mon-Fri(21 Days) | Timing 10:00 AM to 12:00 PM (IST) | Enroll Now |
| Jun 1st | Mon-Fri(21 Days) | Timing 10:00 AM to 12:00 PM (IST) | Enroll Now |
Only Big Data Course In Chennai That Provides Data Experiential Learning!

Big Data Hadoop Training And Placement in Chennai - Why Infycle?
We, Infycle Training Provides The Following Benefits:
- Trainees will get a prompt response to any training related questions, either specialized or something else. We prompt our learners not to hold up until the following class to look for answers to any specialized issue.
- Training meetings are directed by a well-experienced instructor with ongoing models.
- As a feature of this training, you will be dealing with projects and assignments that have gigantic implications in real industry situations, therefore helping you quickly track your profession easily.
- Toward the end of this training program, there will be tests that neatly reflect the sort of inquiries posed in the particular certification tests and assist you with scoring better.
- Infycle effectively gives placement to all trainees who have effectively finished the training.
Interested? Let's get In Touch!
Join Infycle For Learning In-Depth Technology With A Bright Career!
Best Big Data Hadoop Training In Chennai - Infycle:
Excelling Interviews With Live projects:
The most significant question you will be asked is, your proficiency & expertise in Big Data and “What are the projects you have worked on?”. With Infycle, you can able to answer every question like a pro! Besides, our training and projects we taught you will help you to handle the tasks effortlessly.
Trust Built For Infycle Big Data Hadoop Training In Chennai:
Since our brand “Infycle” widely trusted by most of the top MNC’s & organizations for it’s quality of training. So, your profile will have high level standards to attract any type of companies.
Upgrade Your Skills Every Day With Infycle:
At regular intervals, our trainers will come up with new experiments, ideas, tools, technologies to sharpen your skill. For an instance, along with the Big Data and Hadoop, learn the Full Stack Developer Course in Chennai for getting the additional knowedge. Like this, we arrange alternative week Webinars, Podcasts, online training sessions through which you can gain values & knowledge.
Success Story Of Our Big Data Training And Placement In Chennai
Best Big Data Hadoop Training In Chennai - Infycle:
Benefits Of Big Data Includes Several Known And Unknown Benefits And Some Of Them Are Exclusive.

Find Better Solution!
Are you still not aware about the course? Infycle is open to clarify all your doubts. Reach us for your queries.
Big Data Hadoop Training in Chennai - Infycle Course Assets.
To improve your knowledge and our training modules we explore out our methodologies!
Course Attributes
Our course training is an extreme level of knowledge transfer that could help you in the right way!
| Course Name | Big Data |
|---|---|
| Skill Level | Beginner, Intermediate, Advanced |
| Total Learners | 800+ |
| Course Duration | 500 Hours |
| Course Material |
|
| Student Portal | Yes |
| Placement Assistance | Yes |
Our Schedules
We are available for you in a flexible manner for the best support.
We give you the right path!
We consider your goals and provide you the clear vision of the career growth.

Get the Globalized knowledge
Infycle works with motive of delivering only the best to the students to enhance their skills!
Master up your skills with certification!
Enrich the status of your profile by gaining the certification of the course to upgrade yourself.

FAQ's
We prove our confidence by giving a right solution to you! Some of the solutions provided here.
Who can take up the Big Data course?
Big data is a best, highly demanded and beneficial course. If you are interested then you can take up the training. It is affordable for fresh graduates, experienced developers and other software professionals.
What are the prerequisites for Big Data training?
There are no prerequisites for getting trained in Bid Data course. It is beneficial if you have prior knowledge of programming.
Do Infycle offers Placement after doing big data course?
Infycle is proud to present that we have placed 5000+ students in various reputed firms. Our expert placement team provides 100% placement guidance and helps you to mock the interview and get placed with best offers.
Is there any additional benefits in the training?
Infycle Technologies supports you with the best training sessions. In addition to the course, we support you with projects cases, query session and resume building that adds points to your profile to grab the job opportuinities.
Is Big Data is hard to learn?
No. It is basically a database language and uses general language for easy understanding. With our experienced faculty team at Infycle, we make it more easier to learn.
What is my career scope in Big Data?
With everything going digital, all the firms and industries depend a database to maintain records.So with every changing moment, the career opportunities for big data developer is wide open in all sectors.There is a huge demand for database administrators with high paychecks.
For Queries!
Feel free to resolve your doubts with us. Infycle supports you with the best solution through our experts.
Let's get in touch
Give us a call or drop by anytime, we endeavour to answer all enquiries within 24 hours on business days.
{kind=link}
Reviews
Some of the student's review about the training!

Jasmine Soundarya
Web Developer
Chris jerry
Oracle Administrator
Vanmathi R
Cloud Practitioner
Santhana Kumar
Java Developer
HDFS
Toggle content goes here, click edit button to change this text.
Map Reduce
Toggle content goes here, click edit button to change this text.
Yarn
Toggle content goes here, click edit button to change this text.
Sqoop
Toggle content goes here, click edit button to change this text.
Hbase
Toggle content goes here, click edit button to change this text.
Kafka
Toggle content goes here, click edit button to change this text.
Nifi
Toggle content goes here, click edit button to change this text.
Oozie
Toggle content goes here, click edit button to change this text.
Zookeeper
Toggle content goes here, click edit button to change this text.
Big Data Hadoop Course Content
Bigdata Hadoop Administration Course Content
Introduction to Bigdata and the Hadoop Ecosystem
- Why we need Bigdata
- Real-time use cases of Bigdata Overview
- Introduction to Apache Hadoop and the Hadoop Ecosystem
- Apache Hadoop Overview
- Ingestion and Storage of Data
- Data Locality
- Analysis and Exploration of Data
- Other Ecosystem Tools
Hadoop Ecosystem Installation
- Ubuntu 14.04 LTS Installation through VMware Player
- Installing Hadoop 2.7.1 on Ubuntu 14.04 LTS (Single-Node Cluster)
- Apache Hive Installation
- MySQL Installation
- Apache Sqoop and Flume Installation
- Kafka and Spark Installation
- Scala SBT Installation
Apache Hadoop File Storage (HDFS)
- Why we need HDFS
- Apache Hadoop Cluster Components
- HDFS Architecture
- Failures of HDFS 1.0
- High Availability and Scaling
- Pros and Cons of HDFS
- Basics File system Operations
- Hadoop FS or HDFS DFS – The Command-Line Interface
- Decommission methods for Data Nodes.
- Exercise and small use case on HDFS.
- Block Placement Policy and Modes
- Configuration files handling
- Federation of HDFS
- FSCK Utility (Heart Beat and Block report).
- Reading and Writing Data in HDFS
- Replica Placement Strategy
- Fault tolerance
MapReduce
- Overview and Architecture of Map Reduce
- Components of MapReduce
- How MapReduce works
- Flow and Difference of MapReduce Version
- YARN Architecture
- Working with YARN
- Types of Input formats & Output Formats
- Examples of MapReduce Tasks
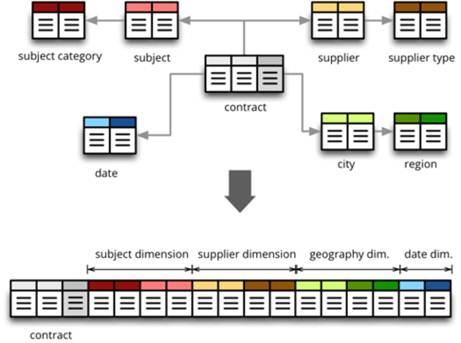
HDFS Infographic
- Reading Data from HDFS
- Writing Data from HDFS
- Replica Placement Strategy
- Fault tolerance
Distributed Processing on an Apache Hadoop Cluster
- Overview and Architecture of Map Reduce
- Components of MapReduce
- How MapReduce works
- Flow and Difference of MapReduce Version
- YARN Architecture
- Working with YARN
Apache Hive
- Installation on Ubuntu 14.04 With MySQL Database Metastore
- Overview and Architecture
- Command execution in shell and HUE
- Hive Data Loading methods, Partition and Bucketing
- External and Managed tables in Hive
- File formats in Hive
- Hive Joins
- Serde in Hive
- Functions in Hive
- String Manipulation in Hive
- Date Manipulation in Hive
- Row-level transformations in Hive
- Indexes and Views in Hive
- Hive Query Optimizers
- Windowing Functions in Hive
Apache Sqoop
- Overview and Architecture
- Import and Export
- Sqoop Incremental load
- Sqoop Eval
- Managing Directories
- File Formats
- Compression Algorithm
- Boundary Query and Split-by
- Transformations and filtering
- Delimiter and Handling Nulls
- Sqoop import all tables
- Column Mapping in Sqoop Export
Apache Pig
- Apache Pig Overview and Architecture
- MapReduce Vs Pig
- Data types of Pig
- Pig Data loading methods
- Pig Operators and execution modes
- Load and Store Operators
- Diagnostic Operators
- Grouping and Joining
- Combining and Splitting
- Filtering and Sorting
- Built-in Functions
- Pig script execution in shell/HUE
Apache HBase
- Introduction to NoSQL/CAP theorem concepts
- Apache HBase Overview and Architecture
- Apache HBase Commands
- HBase and Hive Integration module
- HBase execution in shell/HUE
Apache Spark Basics
- What is Apache Spark?
- Starting the Spark Shell
- Using the Spark Shell
- Getting Started with Datasets and Data Frames
- Data Frame Operations
- Apache Spark Overview and Architecture
RDD and Paired RDD
- Overview of RDD & Data Sources
- Creating and Saving RDDs
- Writing & Passing Transformation Functions
- RDD Operations
- Transformations and Actions
- Converting Between RDDs and Data Frames
- Key-Value Pair RDDs
- Map-Reduce operations
- Other Pair RDD Operations
Working with Data Frames, Schemas and Datasets
- Creating Data Frames from Data Sources
- Saving Data Frames to Data Sources
- Data Frame Schemas
- Eager and Lazy Execution
- Querying Data Frames Using Column Expressions
- Grouping and Aggregation Queries
- Joining Data Frames
- Querying Tables, Files, Views in Spark Using SQL
- Comparing Spark SQL and Apache Hive-on-Spark
- Creating Datasets
- Loading and Saving Datasets
- Dataset Operations
Writing, Configuring and Running Apache Spark Applications
- Writing a Spark Application
- Building and Running an Application
- Application Deployment Mode
- The Spark Application Web UI
- Configuring Application Properties
Apache Flume
- Introduction & Features of Flume
- Flume topology & core concepts
- Flume Agents: Sources, Channels, and Sinks
- Property file parameters logic
Apache Kafka
- Installation
- Overview and Architecture
- Consumer and Producer
- Deploying Kafka in real-world business scenarios
- Integration with Spark for Spark Streaming
Apache Zookeeper
- Introduction to Zookeeper concepts
- Overview and Architecture of Zookeeper
- Zookeeper principles & usage in Hadoop framework
- Use of Zookeeper in HBase and Kafka
Apache Oozie
- Oozie Fundamentals of Oozie
- Oozie Workflow creations
- Concepts of Coordinates and Bundles
Big Data Hadoop Development Course Content
Introduction to Scala
- Functional Programing Vs Object Orient Programing
- Scala Overview
- Configuring Apache Spark with Scala
- Variable Declaration
- Operations on variables
- Conditional Expressions
- Pattern Matching
- Iteration
Deep Dive into Scala
- Scala Functions and Oops Concept
- Scala Abstract Class & Traits
- Access Modifier, Array, and String
- Exceptions, Collections, and Tuples
- File handling and Multithreading
- Spark Ecosystem
CCA Certification Course Content
Querying Tables and Views with Apache Spark SQL
- Spark with Querying Tables Using SQL
- Querying Files and Views
- The Catalog API
- Comparing Spark SQL, Apache Impala, and Apache Hive-on-Spark
Working with Datasets in Scala
- Datasets and DataFrames
- Creating Datasets
- Loading and Saving Datasets
- Dataset Operations
Distributed Processing
- Review: Apache Spark on a Cluster
- RDD Partitions
- Example: Partitioning in Queries
- Stages and Tasks
- Job Execution Planning
- Example: Catalyst Execution Plan
- Example: RDD Execution Plan
Distributed Data Persistence
- DataFrame and Dataset Persistence
- Persistence Storage Levels
- Viewing Persisted RDDs
- Difference between RDD, DataFrame, and Dataset
Common Patterns in Apache Spark Data Processing
- Common Apache Spark Use Cases
- Iterative Algorithms in Apache Spark
- Machine Learning
- Example: k-means
Apache Spark Streaming: Introduction to DStreams
- Apache Spark Streaming Overview
- Example: Streaming Request Count
- Developing Streaming Applications
- Print and Saving tweets
- Explain how stateful operations work
- Explain window and join operations
Apache Flume
- Introduction to Flume & features
- Flume topology & core concepts
- Flume Agents: Sources, Channels and Sinks
- Property file parameters logic
Apache Spark Streaming: Processing Multiple Batches
- Multi-Batch Operations
- Time Slicing
- State Operations
- Sliding Window Operations
- Preview: Structured Streaming
Apache Spark Streaming: Data Sources
- Streaming Data Source Overview
- Apache Flume and Apache Kafka Data Sources
- Example: Using a Kafka Direct Data Source
Certificate List
Earn a professional certificate from top universities and institutions including Harvard, MIT, Microsoft and more.
Interested? Let's get in touch!
Infycle offers you the best in class software training with 100% practical sessions and assured placement assistance. Call us to know more!
Infycle’s Big Data Course In Chennai - What’s This Program About?
“Inspired by industry and driven by student success”
The program enables you to
- Build your resume to grab a recruiter attraction and leave an extraordinary initial introduction in any company you join in.
- Reclassifying your career objectives and molding your portfolio to assist you “TO STAND OUT IN A GROUP”.
- Pretending during a mock interview and Q&A rounds to intellectually set you up for progress.
Big Data Course – Introduction:
- Big Data Course in Chennai offers further knowledge about the importance of data sets by recounting the story behind the data.
- This empowers partners to settle on progressively educated choices. This program furnishes students with an exceptional mix of hypothetical information and applied skills.
- Students will learn about how to gather, control, encode, and store data indexes so they can be analyzed and mined.
Career Opportunities of Big Data Course in Chennai!
“Inspired by industry and driven by student success”
Utilizing earlier foundation, aptitudes, and experience, students and working employees might be utilized in jobs, for example, Data Analyst and Data Scienctist, Data Visualization Developer, BI Specialist, etc.
Top 12 Companies hiring for Big Data Course in Chennai
Hadoop is an open source platform that runs huge amounts of unstructured data in commodity hardware with great flexibility across the web. Here are some of the top companies which follow Hadoop clusters in their businesses:
- Amazon web services
- Cloudera
- Sciencesoft
- Pivotal
- Hortonworks
- IBM
- Microsoft
- MapR
- Datameer
- Hadapt
- Adello
- Karmasphere
Latest Blog

Landing your first job as a software developer can feel overwhelming, especially when you are stepping out of college with theoretical knowledge but limited real-world experience. Java, […]

Stepping into the professional world right after graduation can be daunting, particularly when employers expect both domain knowledge and hands-on experience. How Fresh Graduates Can Build a […]

The rapid growth of artificial intelligence has ignited widespread discussions in many industries — and the technology sector is no different. As AI-powered coding assistants become increasingly […]
Student testimonials
We are very proud of the service we provide and stand by every training we carry. Read our testimonials from our successful students.
Trending Courses
| Oracle SQL | Oracle PLSQL | Oracle DBA | Big Data | AWS | Azure | DevOps | Java | Python | Digital Marketing | Data Science |
| Web Development | Full Stack Development | AngularJS | Dot Net | Selenium | Salesforce | Android | iOS | Mainframe |